

If you are interested in just seeing the data for Desert Island Discs, you can download it here.
Note: since this article was first posted (4 Feb 2020), the output has been updated. So the numbers in the summaries below are out of date but the latest data is provided in the output files.
Introduction
I was curious to find out more about BBC Radio 4’s Desert Island Discs but couldn’t find a spreadsheet with all the data. So I wrote a program to extract the data from the BBC website.
The top ten books and the number of times they were chosen are:
| No. | Book | Number of times chosen |
|---|---|---|
| 1 | War and Peace by Leo Tolstoy | 39 |
| 2 | Encyclopaedia Britannica | 32 |
| 3 | A La Recherche Du Temps Perdu by Marcel Proust | 32 |
| 4 | Encyclopaedia | 30 |
| 5 | The History of the Decline and Fall of the Roman Empire by Edward Gibbon | 18 |
| 6 | The Oxford Book of English Verse | 17 |
| 7 | The Wind in the Willows by Kenneth Grahame | 15 |
| 8 | The Lord of the Rings by J R R Tolkien | 14 |
| 9 | The Oxford English Dictionary | 13 |
| 10 | The Pickwick Papers by Charles Dickens | 13 |
Of the music played, here are the top musicians:
| No. | Musician | Number of times chosen |
|---|---|---|
| 1 | Wolfgang Amadeus Mozart | 969 |
| 2 | Ludwig van Beethoven | 819 |
| 3 | Johann Sebastian Bach | 762 |
| 4 | Franz Schubert | 395 |
| 5 | Giuseppe Verdi | 361 |
| 6 | Giacomo Puccini | 335 |
| 7 | Edward Elgar | 328 |
| 8 | George Frideric Handel | 300 |
| 9 | The Beatles | 291 |
| 10 | Peter Ilyich Tchaikovsky | 271 |
| 11 | Johannes Brahms | 260 |
| 12 | Frank Sinatra | 250 |
| 13 | Richard Strauss | 223 |
| 14 | Claude Debussy | 184 |
| 15 | Sergey Rachmaninov | 178 |
| 16 | Benjamin Britten | 166 |
| 17 | Maurice Ravel | 161 |
| 18 | Ralph Vaughan Williams | 160 |
| 19 | Jean Sibelius | 153 |
| 20 | Felix Mendelssohn | 151 |
| 21 | Gustav Mahler | 141 |
| 22 | Igor Stravinsky | 123 |
| 23 | Ella Fitzgerald | 120 |
| 24 | Édith Piaf | 119 |
| 25 | William Shakespeare | 114 |
| 26 | Bob Dylan | 109 |
| 27 | Antonín Dvořák | 109 |
| 28 | Joseph Haydn | 108 |
| 29 | Noël Coward | 105 |
| 30 | Arthur Sullivan | 104 |
It’s interesting how classical music dominates the top ten apart from The Beatles.
The top twenty luxuries chosen are:
| No. | Luxury | Number of times chosen |
|---|---|---|
| 1 | Piano | 137 |
| 2 | Writing materials | 64 |
| 3 | Painting materials | 43 |
| 4 | Guitar | 36 |
| 5 | Bed | 32 |
| 6 | Radio receiver | 28 |
| 7 | Golf clubs and balls | 28 |
| 8 | Typewriter and paper | 25 |
| 9 | Telescope | 23 |
| 10 | Pen and paper | 19 |
| 11 | Champagne | 19 |
| 12 | Wine | 16 |
| 13 | Perfume | 15 |
| 14 | Tape recorder | 14 |
| 15 | Typewriter | 13 |
| 16 | Binoculars | 13 |
| 17 | Family photo album | 10 |
| 18 | Tea | 9 |
| 19 | Soap | 9 |
| 20 | Paper and pencils | 9 |
If you want a list of all episodes, the music played, and the books, luxuries and favourite tracks chosen, you can find them here. The list is available as an Excel spreadsheet and a CSV file. The Excel spreadsheet has the full list of top books, musicians, and luxuries.
The rest of this post is about how I wrote the Python program to create the spreadsheet.
Background
I was learning Python as part of a machine learning course. This was a good opportunity to write a full program in Python with an actual use case, which would allow me to learn more Python concepts.
Choosing a web scraping framework
My first task was to find a library that would make scraping data from a website easy. There are many websites listing Python frameworks. One of them is ScrapHero. After looking at the pros and cons, I choose BeautifulSoup 4 (BS4). It was relatively easy to learn, robust and had good documentation.
I downloaded BS4 and instantly became productive. So I stuck to it and looked no further. If your needs are more complex, you may want to look at other frameworks.
Web scraping basics
It had been a long time since I’d done any web scraping. I can’t even remember which language I used at the time.
This is the basic process for scraping data off a website:
-
Find the web page you want to extract data from.
-
Look at the structure of the page using the developer tools of your browser. Both Chrome (and derivatives) and Firefox have good developer tools.
-
Find the data you want on the page.
-
Press
Ctrl-Shift-cto inspect the source code of the element. -
Work out how to navigate to that element using HTML and CSS.
-
Write code!
Example of scraping web data
If you learn from source code, you can go straight to the source code on Github.
I’m going to use the Michael Lewis Desert Island Discs episode for this example.
Here’s a view of the tracks chosen by Martin Lewis and a view of the inspector:
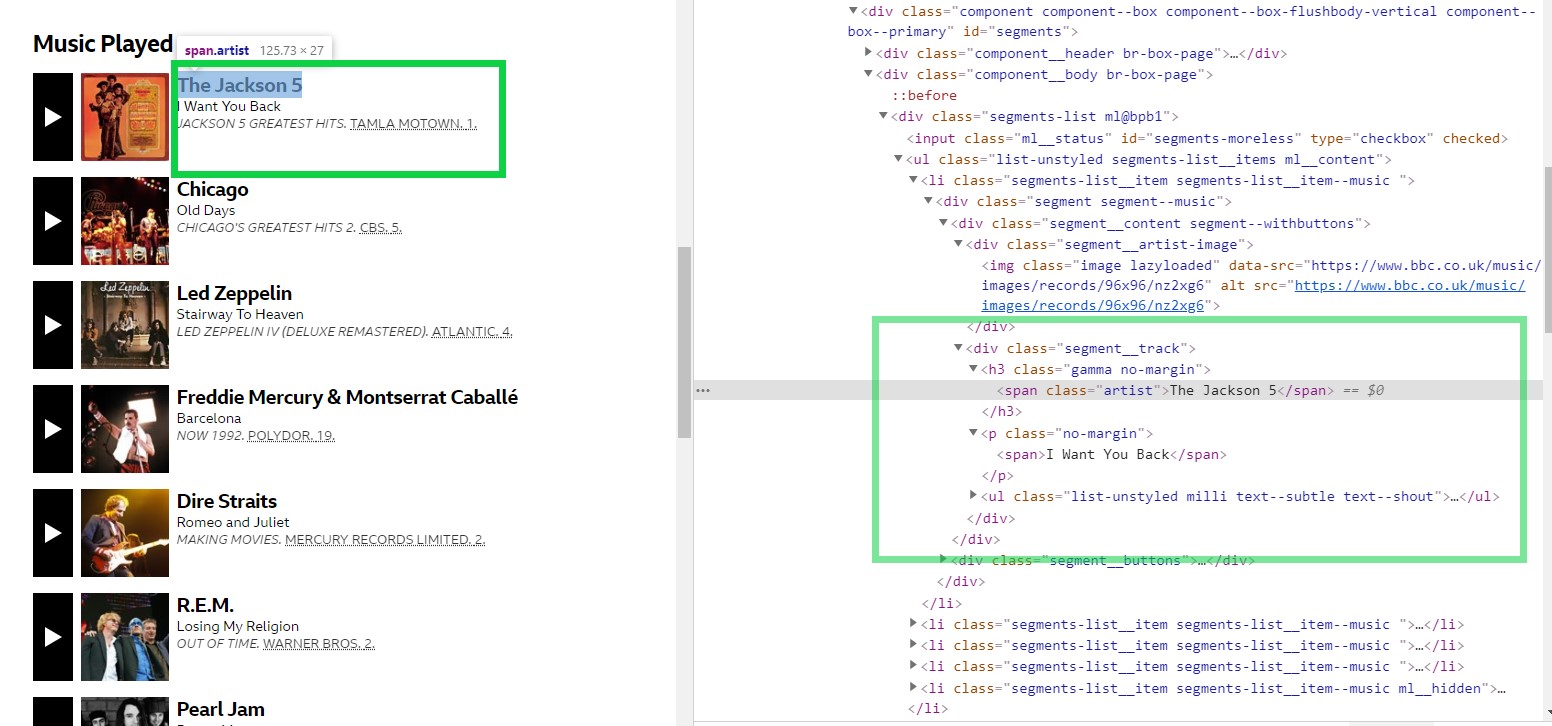
On the left side in the above screenshot, you’ll see a track highlighted: I want you back by The Jackson 5. On the right side is the source code for it. (You may need to zoom in to read the screenshot.) By looking at the code, you can see that the tracks are described in a <div> with CSS class segment__track. Within the <div>, is an <h3> tag containing a <span> tag (with class artist) that has the name of the artist. Below that, as a <p> tag, is a <span> tag with the name of the song.
The code to extract track data is in scraper.py and the relevant methods are shown below:
def extract_tracks_from_list(self, soup):
"""
The episode page has a structured list of episodes usually.
"""
tracks = TrackList()
tracks_element = soup.find_all('div', class_='segment__track')
for track_element in tracks_element:
try:
track = self.extract_artist_and_song_from_list(track_element)
tracks.add(track)
except Exception as e:
print_error(f'Ignoring error extracting song/artist from element: {track_element}', e)
return tracks
def extract_artist_and_song_from_list(self, track_element, class_='artist'):
artist = ''
gysong = ''
if track_element:
# Sometimes there is more than one artist, in which create comma-separated list
artist_element = track_element.find_all('span', class_)
for e in artist_element:
artist += ' & ' if artist else ''
artist += e.text
song = track_element.p.span.text if track_element.p.span is not None else ''
return Track(clean_string(artist), clean_string(song))
The method extract_tracks_from_list finds all the <div> elements with class segment__track and iterates over them. The method extract_artist_and_song_from_text extracts the name of the artist and the song title. The artist is extracted by looking for a <span> tag of class class_ (whose value in this instance is artist). The song is extracted by looking for a for <p> tag with a <span> tag (track_element.p.span.text).
Program structure
The program is written in an object-oriented way. I did some fairly basic object-oriented analysis to determine the classes. In the following description of Desert Island Discs, the italicised words become classes in the program:
Desert Island Discs has people on it who are called castaways. Each castaway appears in his or her own episode. The castaway has a name and job title. Each episode has a URL on the BBC website. The castaway picks a track list, which consists of up to eight tracks. A track consists of an artist and a song. The castaway also picks a favourite track, a book and a luxury to take to the desert island. The program will require a parser to extract data from the BBC website and an output writer to display the data in a formatted way.
Data complications
Hopefully, you’ve seen how easy it is to extract data. Data being data, the greatest difficulty is that data is not represented consistently in the real world. The BBC Desert Island Discs website has over 3,000 episodes. For these, there are several variations for representing the same data. For example, sometimes the tracks don’t appear as a nice list (as above) but instead in the text describing the episode, like this:

Similarly, the luxury, book and favourite track can appear in several places. They are also denoted by different phrases, such as "Favourite", "Favourite track", "Castaway’s Favourite" and so on.
To extract some data, Python regular expressions are used. You may want to read about them if you’re not familiar (although most of the regular expressions used are fairly simple).
The program does a reasonable job of extracting most information for most episodes. It tries a number of ways of extracting data if the default method fails.
However, successfully extracting data from a website depends on the structure of the website and the pages on it. If the URLs, HTML or CSS change, the program is likely to fail, depending on how drastic the change is.
Output
The program can output the data it finds in a CSV file. By default, the delimiter is a tab. From this tab-delimited file, I’ve created an Excel spreadsheet. You can see details for all episodes of Desert Island Discs in the spreadsheet. You’ll sometimes see missing data. Where data has not been extracted, it’s usually because it has been represented in an uncommon way on the website. To check if the program didn’t extract the data or if it’s missing on the BBC website, you can click the link for the episode.
To import the output CSV file into Excel 2016:
- Open a new spreadsheet.
- Put the cursor on cell A1.
- Click the Data tab in the toolbar.
- Click From Text.
- Select the CSV file.
- In the Text Import Wizard:
- Select Delimited.
- In the File Origin, select 65001: Unicode (UTF-8).
- Click Next.
- Select Tab as the delimiter (ensure other delimiters are not selected).
- Click Next.
- Select General as the Column data format.
- Click Finish.
The spreadsheet in Github has other formatting and hyperlinking added.